The curl command is grabbing the actual information from your own EKG port on localhost:12788
date - time calculations
ps as a simple way to grab the RTS settings when the node was started
ss to list the established connections
I leave it as a cut and paste thing because it is easy to grab from the previous command history and there are only a few commands in it. I really think it is a bad security idea to blindly rely on other people’s scripts though, and especially ones that get somehow automatically updated on your system. The best thing to do is steal my code above, run each line separately and ensure you know what it does, then modify it to suit your needs. Then you have much better security practices with no additional “tools” required.
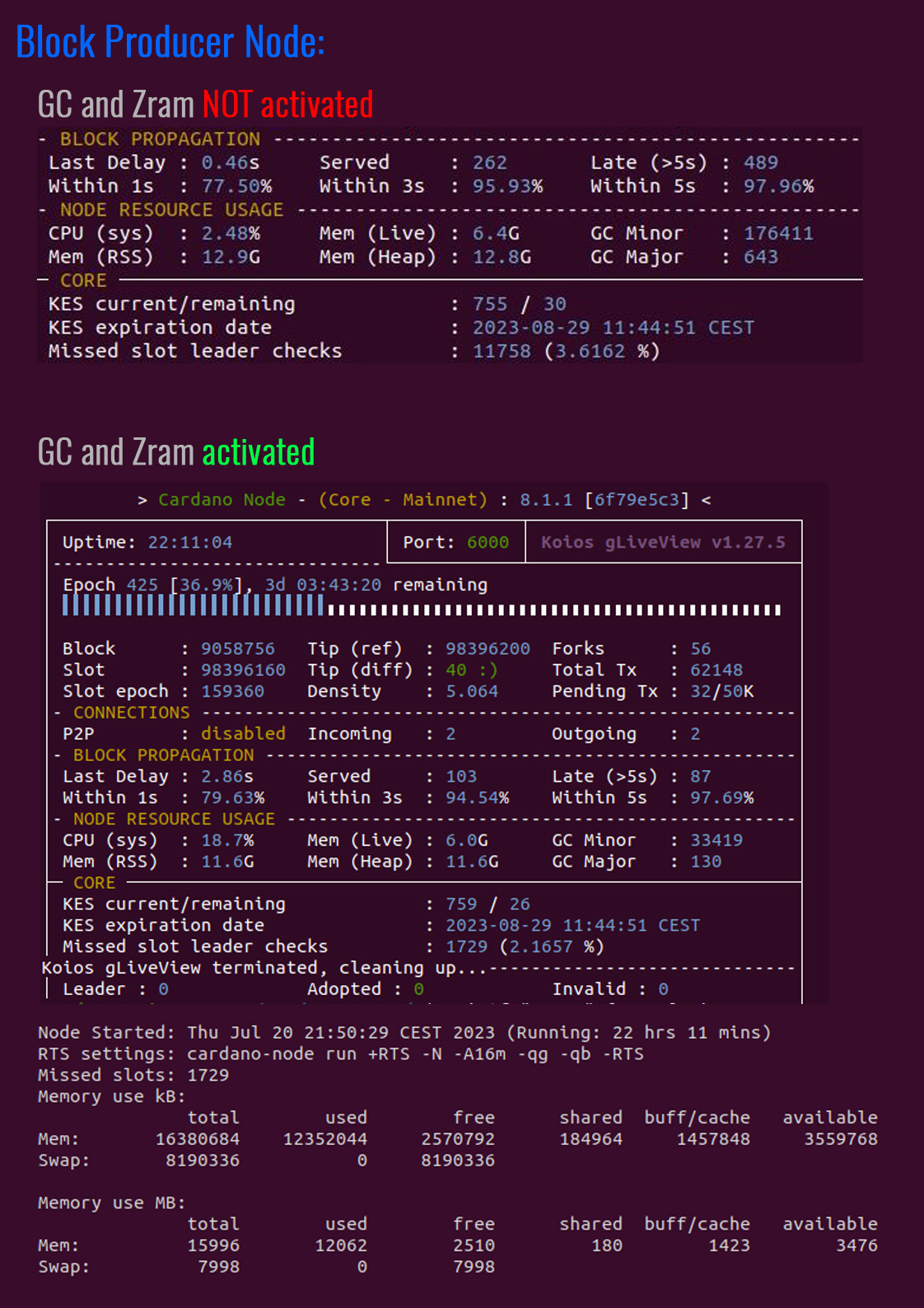
At first glance it seems like my BP and RELAY’S are still running out of memory with the ZRAM applied? Assuming that the sum of the live and heap memory determines the total required RAM?
However the metrics say there is about 3GB RAM free on both nodes.
So not sure it’s really necessary to upgrade to min 24 GB RAM?
Update on the pool.
All nodes (BP en 2 Relays) are now upgraded to 30GB RAM, 8 x 2.8~3.2 CHz CPU cores and 800GB SSD with 600 Mbits/s network each and are running Cardano Node 8.1.1
I’ll monitor if the missed slot leader checks still occur the coming days.
24 hours checkpoint using the new system with each 30GB RAM and 8 x 2.8 ~3.2 GHz CPU cores.
GC trick applied and Zram installed. (See installed method used Implementation used)
Not sure if the GC implementation is correct to use with the Cardano node?
Still getting around 2.5% missed slot leader checks. But the system in getting regular blocks adopted.
Ok. From my own experience, with 30GB you don’t have any RAM problem…
So first of all, change your swappiness parameter (you don’t need to swap often…)
vm.swappiness = <try 10 or 20…>
Also, you coult try to optimize your RAM with cache pressure. This parameter move more or less data that is not going to be used immediatly from RAM to SWAP. Default is 100. Try 50.
vm.vfs_cache_pressure=50
The main cause behind those missed slots is probably those shared vCPU on VPS Contabo… Unfortunatly, there isn’t much you can do about that (unless you go for a VDS or a full Dedicated Barebone Server).
You could try these options on your BP inside your cardano startup script, and see if it improves your missed slots % :
The BP has been running for 4 days. The missed slot leader check is currently around 1.3%
after adding the “SnapshotInterval”: 43200, to the config file.