Hello Everyone, I hope that things are great. I have noticed a large increase in the “missed slot leader checks” on my stakepool - currently, after 13 hours of running, I’m at 3,160 missed slot leader checks or 6.7%. I have tried applying the solutions found in the following links, but nothing seems to make a difference, links →
My BP is running on a Contabo VM (VPS S), 4 vCPU cores, 8GB RAM with a 10GB swap setup, hosted in Germany. My BP was prepared following the CoinCashew tutorial.
I recently updated to cardano node version 1.30.1 although I must admit, I didn’t really check this point when I was running the previous cardano node version.
Does anyone know what I am doing wrong? Thanks so much, Simon
8gb of ram are not enough if not used smartly. I suggest you try zram or other ram swapping tools, to increase the effective usable ram. You have plenty of CPU power.
Unfortunately, this didn’t work, I still have missed slot leader checks. I will try upgrading my VM to include more RAM - so you know if there a lower limit that one should be at? Thanks
I can confirm that 8GB is not enough for a producer node (10GB is the current minimum IMHO), even zram will use the CPU and slow down your node causing missed slots (depending on your cpu speed and vps quality)…
Hey @houseofcardano, where are you running your nodes? If it has shared CPU resources, then that’s probably one of the issues. I suggest you upgrade at least the block producer node with dedicated CPU resources and you’ll see a huge difference.
8GB of RAM should be fine under certain conditions and depending on your server configuration, take care of not taking any stake snapshot in that same node since that’s memory intensive and the cardano-node process might crash.
Hi Guys, I upgraded my BP - the next tier up has 16GB of RAM & 6 CPU
But I’m still getting missed slot leader checks although much less than before (I’m at 0.3% after 11 1/2 hours of up time). Don’t know what I can do now. I read somewhere that at the end of an epoch missed slot leader checks occur more often and we’re currently 5 hours away from the end of the epoch - I don’t know if this could influence anything?
Anyway, thanks everyone for the suggestions that you made. Warm regards, Simon
If you want to stay at 8GB RAM, you can try to put a limit on the memory usage to avoid swapping, which is what is likely causing the huge number of missed slots:
+RTS -N -M7.2g -A16m -n1m -O512m -T -I0 -c50 -qb0 -RTS
Im not sure what an acceptable number of slot leader check losses are but im pretty sure im also on the wrong side of an acceptable range. I am running Blockp on 2vCPU 2 Cores @ 2.5GHz and 16GB memory. There seems to be alot of conjecture around what is the solution to this problem with anything from garbage collection to cardano node settings and its all fairly involved.
In 20Hrs 45Mins I have ~285 Missed Slot leader checks. What is an acceptable number?
If there is a slot every second that means that im missing … 20 * 3600 + 45 * 60 = 72000 + 2700 = 74700
285/74700 * 100 = 0.385 % of Slots Missed or 3.8 in 1000 slots (I don’t know but I imagine something closer to ~1 in 1000 or even 1 in 10 000 would be ideal?
I installed chrony on all nodes/blockproducer I have 2 Relays 1 directly listed/registered with the BlockP and 1 that is linked but not officially registered with the pool.
The blockp has the 2 relays as the only peers in and out. Both relays have ~20 peers the local relay has a RTT of around 0ms and the second relay around 300
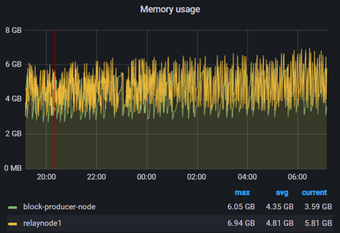
The memory and CPU all look fairly stable during this period
Hi, unfortunately not. I tried everything I could find online & also the tips from everybody that was kind enough to reply, but I’m still having missed slots. I upgraded my BP to a higher spec machine, now I’m wondering whether I also have to upgrade the nodes too? Do you have any ideas? Cheers, Simon
I have a 6vCPU with 32G RAM and I also have missed slots… but this will not lead to lose blocks … as far as I know everyone has these missed slots… ignore them
Probably need more data but following [SHARD] Pools great article Solved: How to minimise Missed Slot Leader checks / missed blocks with stake pool ADA Cardano node - How to get stuff done. to “change the Garbage Collection to use Nonmoving-GC which uses the newer concurrent mark-and-sweep garbage collector, and it doesn’t block other processes.” Seems to have reduced the missed slots I have been seeing. I also tried changing from timedatectl NTP to chrony NTP which did not seem to have much impact - but using chronyc tracking is a great tool to see how the timesync is performing.
As per the recommendation -
add the following line to your .bashrc file (credit orpheus-ant)
export GHCRTS=’-N -T -I0 -A16m --disable-delayed-os-memory-return --nonmoving-gc’
Its too early to tell but initial stats look promising for my case as the missed slots have roughly halved