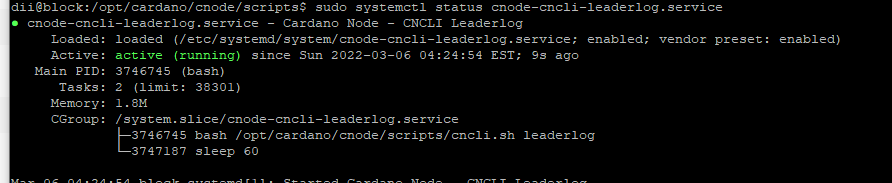
Can someone please tell me what happened? Is it a false alarm?


{"host":"block","pid":"3741687","loc":null,"at":"2022-03-04T17:22:57.89Z","ns":["cardano.node.KeepAliveClient"],"sev":"Info","env":"1.34.0:c23d5","data":{"outboundG":0.124358388388,"kind":"KeepAliveClient AddSample","rtt":0.242788247,"address":"ConnectionId {localAddress = 192.168.0.10:36553, remoteAddress = 194.233.92.68:6000}","sampleTime":"1026451.561875313","inboundG":0.124358388388},"msg":"","thread":"164945","app":[]}
{"host":"block","pid":"3741687","loc":null,"at":"2022-03-04T17:22:58.00Z","ns":["cardano.node.LeadershipCheck"],"sev":"Info","env":"1.34.0:c23d5","data":{"utxoSize":6016578,"kind":"TraceStartLeadershipCheck","delegMapSize":1169370,"credentials":"Cardano","slot":54848287,"chainDensity":4.6236213e-2},"msg":"","thread":"416","app":[]}
{"host":"block","pid":"3741687","loc":null,"at":"2022-03-04T17:22:58.00Z","ns":["cardano.node.Forge"],"sev":"Info","env":"1.34.0:c23d5","data":{"val":{"kind":"TraceNodeNotLeader","slot":54848287},"credentials":"Cardano"},"msg":"","thread":"416","app":[]}
{"host":"block","pid":"3741687","loc":null,"at":"2022-03-04T17:22:59.00Z","ns":["cardano.node.LeadershipCheck"],"sev":"Info","env":"1.34.0:c23d5","data":{"utxoSize":6016578,"kind":"TraceStartLeadershipCheck","delegMapSize":1169370,"credentials":"Cardano","slot":548