Exactly… contabo is not the best provider when we talk about performance… but its the cheapest… and for pools which don’t mint blocks and no incomes is excelent ![]()
Cheers,
Exactly… contabo is not the best provider when we talk about performance… but its the cheapest… and for pools which don’t mint blocks and no incomes is excelent ![]()
Cheers,
Thanks for all the replies, opened up a can of worms I see :).
Missed slot leader checks : 2944 (1.3966 %)

I see my Node2 taking high Sync errors (they are all set up the same from Alex’s guide).
I did a hardware check on what Contabo is providing, my Node2 is different than my Node1 and Producer which are not taking these errors.
Someone with more knowledge than I see any possible reason why Node2 would be taking higher sycn errors?
Alex is correct, I’m never going to make money doing this, I like to tinker and support the network though.
Any help would be appreciated.
Producer:
description: Computer
product: Standard PC (i440FX + PIIX, 1996)
vendor: QEMU
version: pc-i440fx-4.1
width: 64 bits
capabilities: smbios-2.8 dmi-2.8 smp vsyscall32
*-core
description: Motherboard
physical id: 0
*-firmware
description: BIOS
vendor: SeaBIOS
physical id: 0
version: rel-1.12.1-0-ga5cab58e9a3f-prebuilt.qemu.org
date: 04/01/2014
size: 96KiB
*-cpu
description: CPU
product: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
vendor: Intel Corp.
physical id: 400
bus info: cpu@0
version: pc-i440fx-4.1
slot: CPU 0
size: 2GHz
capacity: 2GHz
width: 64 bits
NODE1:
description: Computer
product: Standard PC (i440FX + PIIX, 1996)
vendor: QEMU
version: pc-i440fx-4.1
width: 64 bits
capabilities: smbios-2.8 dmi-2.8 smp vsyscall32
*-core
description: Motherboard
physical id: 0
*-firmware
description: BIOS
vendor: SeaBIOS
physical id: 0
version: rel-1.12.1-0-ga5cab58e9a3f-prebuilt.qemu.org
date: 04/01/2014
size: 96KiB
*-cpu
description: CPU
product: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
vendor: Intel Corp.
physical id: 400
bus info: cpu@0
version: pc-i440fx-4.1
slot: CPU 0
size: 2GHz
capacity: 2GHz
width: 64 bits
Differences:
version: pc-i440fx-4.1 Producer and Node1
version: pc-i440fx-5.2 Node2
CPU Node2:
*-core
description: Motherboard
physical id: 0
*-firmware
description: BIOS
vendor: SeaBIOS
physical id: 0
version: rel-1.14.0-0-g155821a1990b-prebuilt.qemu.org
date: 04/01/2014
size: 96KiB
*-cpu
description: CPU
product: AMD EPYC 7282 16-Core Processor
vendor: Advanced Micro Devices [AMD]
physical id: 400
bus info: cpu@0
version: pc-i440fx-5.2
slot: CPU 0
size: 2GHz
capacity: 2GHz
width: 64 bits
CPE Node1 and Producer:
*-core
description: Motherboard
physical id: 0
*-firmware
description: BIOS
vendor: SeaBIOS
physical id: 0
version: rel-1.12.1-0-ga5cab58e9a3f-prebuilt.qemu.org
date: 04/01/2014
size: 96KiB
*-cpu
description: CPU
product: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
vendor: Intel Corp.
physical id: 400
bus info: cpu@0
version: pc-i440fx-4.1
slot: CPU 0
size: 2GHz
capacity: 2GHz
width: 64 bits
To add< did implement these changes:
CPU_CORES=4
MEMPOOL_BYTES=8388608
Keep in mind that all nodes (BM, VPS, etc) have missed slots during the epoch transition
You are 100% fine
My BP which is BM at home in Romania has 15ms and never lost a block because of this


Yes, Alex, all Block Producers have missed slot leader checks during epochs transition. But the number was around 120-130 for this epoch transition. The rest or more than 2800 in 2 days and 10 hours is because of the hosting quality ![]()
@Fawah move the BP on hetzner or another VPS provider (or use VDS) if u want to see 0.
The shortcut VPS stands for “Virtual Private Server”.
The part “Virtual” may indicate that it runs on a Virtualization layer.
And the shortcut VPS is just one of many,… VM (Virtual Machine) is just another one.
Nearly none of them indicate if resources are shared to dedicated.
So you can keep saying shared resources are in the “nature” of a VPS, but repeating it does not make it a reality.
@Alexd1985 and all the others.
Read carefully, what I wrote, my major statement was that you get what you pay for and it is basically russian roulette - if your server is not over-filled with too many VPS then the experience MAY be okay, till the point where there are TOO MANY customers on one server and/or the Desktop PC breaks.
But here are some pictures, which speak louder than 1000 words:

That is a tiny picture from Contabo’s blog. But if you run some checks you can find a bigger one,
where you can see things more clearly:

I am in the datacenter colocation business for over 25+ years, so “don’t educate/tell plumber how shit smells”
Another very convincing contabo location:

And if you think, maybe they just do not like 19" Rack-Form-Factor, so they go for some kind of Dell Desktop-Server stuff (which still can have some quality level and real server hardware in it)…
This picture is an official posting from the contabo twitter:
And if you ever checked Desktop-PC cases, you can clearly see that is the cheapest of the cheapest shit you can probably get.
That is what I expect from a Server-Case, USB, and connection for my Microphone/Headset in the front. hahahaha…
And about the Contabo “Datacenters” itself:
When was it, like 6-8 months ago, an entire contabo “datacenter” went offline because an excavator had accidentally dug up a single cable during highway work.
And the entire datacenter was OFFLINE for 2-3 days!!!
After day 1 or 2 they had setup some Wifi Connection to the outside world, but the speed for everyone was obviously absolutely ridiculous.
So why does a person uses a VPS, Server, or whatever in a datacenter and not @home?
Because @home you do not have the redundancy, well if you go to contabo you may have the same problem as @home when shit hits the fan.
The average market-price of a 4 vCPU / 16 GB RAM VPS, is between $100-120,
while contabo offers you 6 vCPU / 16 GB RAM for $14 - so contabo is nearly 8 times cheaper!
But yeah, you are “all” right,… it’s the same right?
Same server/hardware quality? same performance? same sharing ratio? same redundancy?
NO OFFENSE, but whoever thinks when someone sells you a Porsche for $10 and there may NOT be ANY hook,… then this person is maybe silly?!
If you want to laugh,…go here and scroll down till you reach the replies:
https://twitter.com/ContaboCom/with_replies
Here are some:
Feel free to check out the link above.
There are other providers, which offer VPS/VDS with dedicated CPUs and are actually running in a REAL datacenter.
So now my final message/statement, because I already spammed enough:
ALL of you folks can run on contabo, I really do not care, higher chances for me and others to win a height-battle and/or happily minting your missed block.
I can understand why an SPO with a Pool with tiny/low stake uses contabo, it’s just the cheapest “shit” you can get. And when you get 1 block assign per month or even each 2 month, then you do not need crazy infra 24/7.
But my statement is BABYSIT this block, because if your contabo-host-node is overloaded at this moment, things may go very bad for you.
So please understand that contabo is russian roulette, everything may work for a while, at it some point it may just work anymore at all - it’s up to you how much of a risk you want to have.
When it comes to me, I honor each of my delegators and his trust in my Pool, and therefore I run the best infra which is possible. No matter if we are in a bear-market, no matter if I have low stake (and that is where I also was coming from). I am fully IN.
FUN-Fact, when I see that Pools who write or even guarantee 100% 24/7 uptime and I see they are at contabo,… hahahahahaa… 100% is in general NOT possible, but with contabo?!? good luck with that one!
Here is a picture of one of the colocation I run. It’s not one of my best and also not a super-fancy photo, which is okay, because I want to show an average picture:
Alright,…
Do AS YOU will, it’s your choice - I just wanted to warn you!
Cheers!
I never said u are not right… I just said that at that price… for a small pool which don’t make blocks… contabo its not so worst… thats it
If for u is fine to pay 150-300$ each month to keep 3 nodes up and running without producing blocks its fine…
I can definitely see both sides of this argument. So far I have had OK results with Contabo, but I only run an extra relay using them. If they start underperforming then I will move that relay or, more likely, set up an additional one with a different provider.
Or actually, maybe I just set up another Contabo one in a different region. Because I can have 8 times the number of relays if I use Contabo. It would seem pretty unlikely for all 8, located in different countries, to go down at the same time due to excavators.
Sorry for the jibe, but I think that is the problem being faced by the more professional operators. The reliability of consumer grade gear is often good enough and individual service reliability can often be overcome by having more services.
That was not aimed at you…
I also stated:
I can understand why an SPO with a Pool with tiny/low stake uses contabo [...]
Not trying to start a new discussion or to “attack” you, but that is not how it works in “my world”.
Infra does not get better, if you multiply the shit 8 times, at the end it’s just shit x 8.
BUT in your case, that may work for you. If you have 8 relays, they will most likely not go down all at the same time, and the chances are high that maybe at least one has no resource “shortage” at the moment when it’s needed.
But I would rather prefer 2-3 good relays instead of 8 x beeeep
Plus what do you do if you have a block assigned at a very early slot, and your 8 relays are still in the epoch-switch-process?
Anyhow, take care!
I know. It is just healthy banter.
One of the problems with my “just having more separate relays” argument is that there are bandwidth limits to connect back to the block-producer. The block producer and relays can only have a limited number of incoming connections and if you fill them with poor performers… well…
What do you think is the limit?
Maybe I got you wrong, so I better ask.
I don’t know that there is a hard limit, but IOG recommend relays have no more than 20 peers configured in their topology.json file. But, I run most of my relays in P2P mode so then these configurations become more relevant:
"MaxConcurrencyBulkSync": 2,
"MaxConcurrencyDeadline": 2,
"TargetNumberOfRootPeers": 100,
"TargetNumberOfKnownPeers": 100,
"TargetNumberOfEstablishedPeers": 50,
"TargetNumberOfActivePeers": 20,
If you think about how P2P works: It enables your node to prefer connecting with other relays that it gets new blocks from the fastest. So having lots of slower relays is not going to be beneficial in that metric if your goal is to be well connected, by having other relays like you, in order to get your own blocks propagated fastest.
Note: Slow propagation from your block producer will cause your blocks to be involved in more forks, half of which you will lose.
So I got a VDS:
CLOUD VDS S
3 Physical CoresAMD EPYC 7282 2.8 GHz
24 GB RAM
Fresh install using How to set up a POOL in a few minutes - and register using CNTOOLS
When I get to cd ~/git I get does not exist error.
Created the folder manually.
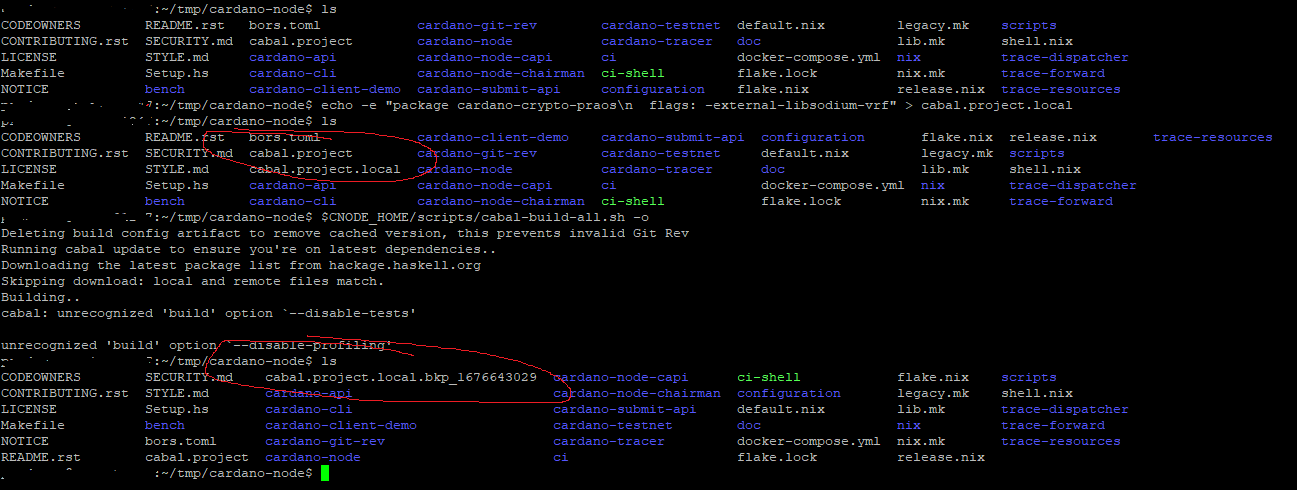
When I get to: echo -e “package cardano-crypto-praos\n flags: -external-libsodium-vrf” > cabal.project.local
$CNODE_HOME/scripts/cabal-build-all.sh -o
I get:
Deleting build config artifact to remove cached version, this prevents invalid Git Rev
Running cabal update to ensure you’re on latest dependencies…
/opt/cardano/cnode/scripts/cabal-build-all.sh: line 76: cabal: command not found
Building…
/opt/cardano/cnode/scripts/cabal-build-all.sh: line 82: cabal: command not found
From cabal-build-all:
cabal update 2>&1 | tee /tmp/cabal-update.log
echo “Building…”
if [[ -z “${USE_SYSTEM_LIBSODIUM}” ]] ; then # Build using default cabal.project first and then add cabal.project.local for additional packages
if [[ “${PWD##/}" == “cardano-node” ]] || [[ "${PWD##/}” == “cardano-db-sync” ]]; then
#cabal install cardano-crypto-class --disable-tests --disable-profiling | tee /tmp/build.log
[[ “${PWD##/}" == “cardano-node” ]] && cabal build cardano-node cardano-cli cardano-submit-api --disable-tests --disable-profiling | tee /tmp/build.log
[[ "${PWD##/}” == “cardano-db-sync” ]] && cabal build cardano-db-sync --disable-tests --disable-profiling | tee /tmp/build.log
I tried installing cabal manually, compile started and thought it was going to go thru but failed.
What am I missing?
did u use/run the new script ./guild-deploy.sh ? I checked inside the script and now git is not used anymore… I added the command to create the git folder, thanks.
old prereqs script
mkdir -p "${HOME}"/git > /dev/null 2>&1 # To hold git repositories that will be used for building binaries
vs new guild-deploy script
mkdir -p "${HOME}"/tmp
for your above errors:
cabal update 2>&1 | tee /tmp/cabal-update.log
[[ "${PWD##*/}" == "cardano-node" ]] && cabal build cardano-node cardano-cli cardano-submit-api --disable-tests --disable-profiling | tee /tmp/build.log
you can delete ~/git folder. lets use tmp from now one…
so try:
cd ~/tmp
git clone https://github.com/input-output-hk/cardano-node
cd cardano-node
git fetch --tags --all
git checkout 1.35.5
echo -e "package cardano-crypto-praos\n flags: -external-libsodium-vrf" > cabal.project.local
$CNODE_HOME/scripts/cabal-build-all.sh -o
Thanks for your help Alex.
Yes running ./guild-deploy.sh
Starting fresh, ran:
mkdir -p “${HOME}”/tmp
__
Edited ./guild-deploy.sh with cabal update 2>&1 | tee /tmp/cabal-update.log line 76 AND
[[ “${PWD##*/}” == “cardano-node” ]] && cabal build cardano-node cardano-cli cardano-submit-api --disable-tests --disable-profiling | tee /tmp/build.log LINE 82
Re-ran $CNODE_HOME/scripts/cabal-build-all.sh -o
Still get lines missing.
I installed cabal manually and re-ran the two updates above.
Now get the below errors:
cabal: unrecognized ‘build’ option --disable-tests' unrecognized 'build' option –disable-profiling’
Also notice after running $CNODE_HOME/scripts/cabal-build-all.sh -o file “cabal.project.local” is removed and replaced with a backup.
See below:
actually u can try to downlod cardano-node and cardano-cli bin files using guild-deploy script
go to tmp file and run ./guild-deploy.sh -s d
Unzip the file then move cardano-node and cardano-cli to /home/user/.local/bin
That worked, easiest install yet, thank you!
From a fresh install:
Ran:
mkdir “$HOME/tmp”;cd “$HOME/tmp”
curl -sS -o guild-deploy.sh https://raw.githubusercontent.com/cardano-community/guild-operators/master/scripts/cnode-helper-scripts/guild-deploy.sh
chmod 700 guild-deploy.sh
./guild-deploy.sh
. “${HOME}/.bashrc”
THEN:
git clone GitHub - input-output-hk/cardano-node: The core component that is used to participate in a Cardano decentralised blockchain.
cd cardano-node
git fetch --tags --all
git checkout 1.35.5
echo -e “package cardano-crypto-praos\n flags: -external-libsodium-vrf” > cabal.project.local
$CNODE_HOME/scripts/cabal-build-all.sh -o
Got same errors but then did as Alex suggested and it worked:
go to tmp file and run ./guild-deploy.sh -s d
Unzip the file then move cardano-node and cardano-cli to /home//.local/bin
Start the node, stop the node, run to download db:
curl -o - https://downloads.csnapshots.io/snapshots/mainnet/$(curl -s https://downloads.csnapshots.io/snapshots/mainnet/mainnet-db-snapshot.json | jq -r ..file_name ) | lz4 -c -d - | tar -x -C /opt/cardano/cnode/
restart node when finished.
Assuming I could have skipped the first run of ./guild-deploy.sh and went right to ./guild-deploy.sh -s d
With this command u will not need to compile the node on future… it will download the bin files already compiled