I think it will not show u if u don’t have missed slots
I checked on mine but not showing since I restarted my server days ago
I think it will not show u if u don’t have missed slots
I checked on mine but not showing since I restarted my server days ago
Cool - just restarted mine as well, probably that is the reason!
Thanks man!
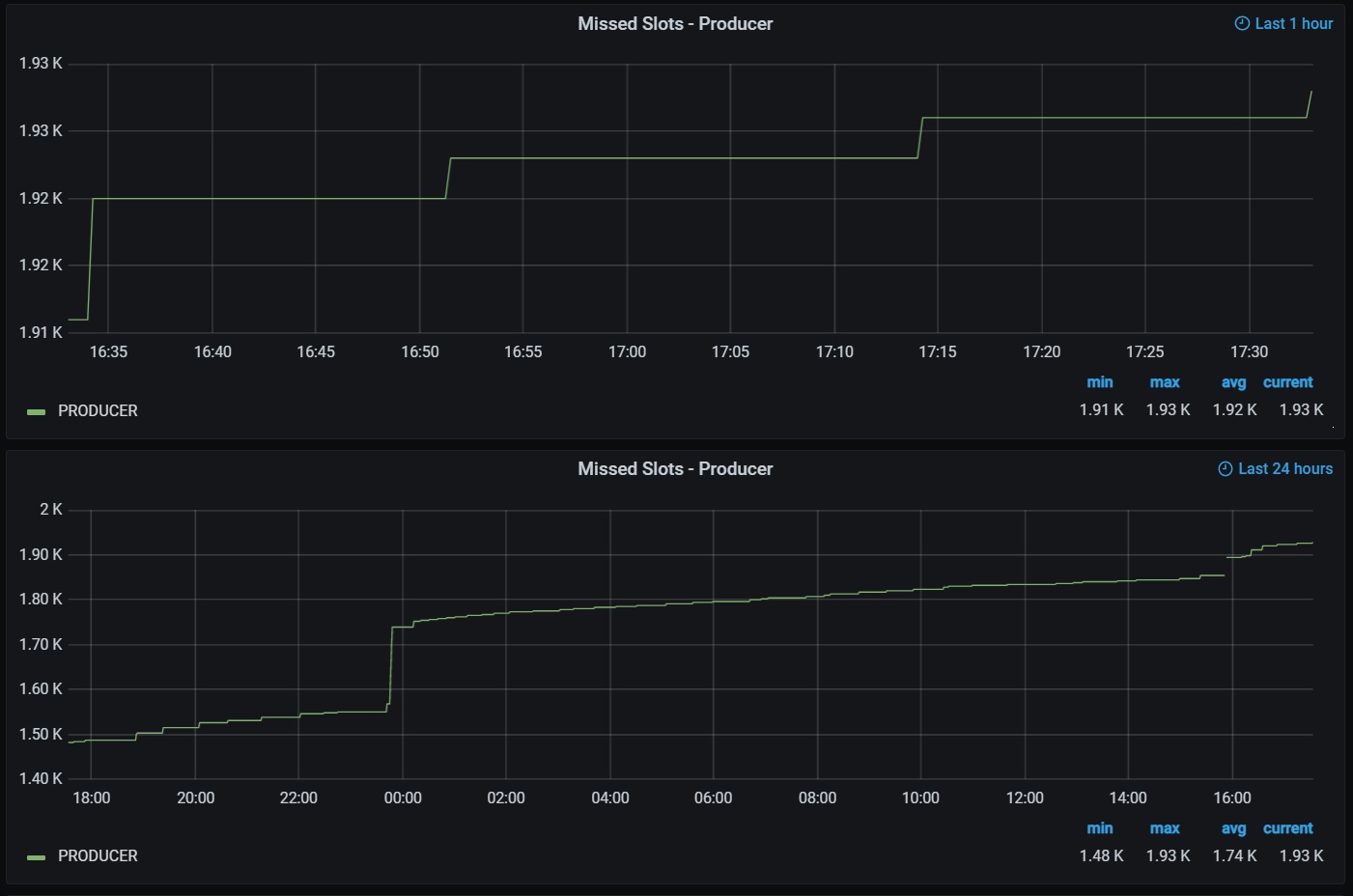
I set TraceMempool to false on my producer node to see if it reduces or eliminates missed slots. Now, Processed TX and MemPool Tx/Bytes are all 0 in gLiveView. Does it rely on TraceMempool for that information? I’d like to not lose that… it’s quite comforting to see it changing…
![]()
Yes unfortunately that’s how it works 
I set it back to true and the numbers are incrementing now. Guess that was it. I’m working on moving my pool to PIs with SSDs instead of the micro sd card they are running on now. Hopefully the faster IO will help.
Can you elaborate on your testing? I would think that missed blocks should not increment if even one of the node relays is (Germany in your case) consistent - regardless of the second relay performance. Isn’t that the point of the redundancy?
To me, this is not an issue about relays - more an issue with BP performance by itself.
I’ve upgraded BP and both relays to 6 vCPU and 16 GB RAM VPS and it does not help.
CPU utilization on BP and both RELAYS are on 5 % average, RAM of 30-40 % average.
It looks like those slots do not interfere with block minting.
I’ve tried reducing maximum peers connected to relays, or shut down one of relays, which looked promising, but then the missed slots continue to appear.
When those missing blocks are happening do you see a peak at CPU usage or a RAM being dumped?
It’s strange because the missed slots occure at each 25 minutes
I have the same problem with the same configuration. Until I restart bp node. Then: no missed slots for about 7 - 10 hours. Afterwards - missing slots again in that way.
My personal guess is some problem with memory management (leak) or some other (invisible short time) stress for the node software.
Next step I’ll try is to setup a second relay node. Until then I’m restarting bp node 2x a day. For me it’s not a big issue since I don’t have that many blocks assigned for now.
There is some little peak in CPU utilization when the slots are missed, but not everytime. RAM utilization is stable.
Yes, restart of BP leads to 5-10 hours period in which none or minimum slots are missed.
How many relay nodes do you have? I’ve upgraded mine to 16 GB RAM as well, because it was running just short of 7 GB with node, cncli sendtips and cncli sync.
I still have no clue, if it’s caused by the bp node or by the relay not being fast enough. Since a slot is exactly a second, missing 22 slots within 10 minutes is quite a lot!
2 relays, each with same config - 6 vCore, 16 GB RAM.
BTW, I also tried to set higher CPU priority for cardano-node process (renice -20) - didn’t work.
After laborious research I can state that the problem of missed slots by BP was in VPS performance (6 vCore, 16 GB RAM, SSD).
Migration of BP to standalone bare-metal server helped and the missing slots totally disappeared.
Glad you got it fixed!
I think bare metal BP is the best setup!
Hello everyone, I occasionally came through this topic while searching for explanations on why maths hasn’t worked yet for my stakepool, I checked on my producer and my grep output was
cardano_node_metrics_slotsMissedNum_int 1324
That was a real surprise to me since i’m running BP and 2 relays baremetal + 1 cloud relay, RTT is everywhere great and the baremetal part of the stakepool is set to have minimum latency and maximum bandwidth priority.
Every server has 8Gb RAM, SSD storage and 4Gb swap, both locals and cloud. Swap was created to mitigate the high RAM usage on version 1.27 (or maybe it’s a standard, can’t remember), but in the last week/10 days i haven’t noticed any high RAM load anymore.
Every server is a clean install, BP is now running cnclisync and sendtip but i implemented these just a couple of days ago, when RAM usage showed constantly around 70% for days. Tracemempool true on all servers.
Is 1324 the number of missed slots from last BP restart or first node run as a producer? If so, what should I do? Set tracemempool as false? Restart BP node periodically? Add RAM and remove swaps? How worried should I be?
I have (I think all SPOs have it) this issue at the start of each epoch…
so, check if during the epoch the missed slots are incrementing… if not then u are fine
Missed 3 more in about 30 minutes, restarted BP node with Tracemempool false, i’ll be strictly monitoring that
Is there a way to know if this issue caused my pool to miss any blocks so far?