yeah but ask them, perhaps being in the same area can be connected via private IP’s
yes i am interested in your tutorial
Yeah I am running my BP on a private subnet (us-east-1) on AWS w/ 1 relay in the same VPC/public subnet (us-east-1) and another relay in another region VPC/public subnet (us-west-1)
Used VPC Peering to connect my BP to other relay (us-west-1). I spun up a Pi Node but can’t find an affordable way to connect to BP since I have to use site-to-site VPN or direct connect.
BP has access to internet by using a NAT gateway.
I am working on tutorials for the pool but its taking some time to create content along with 2 jobs + ongoing interviews for this blockchain job. I will post in forums once I get the chance to make tutorials 
I can help you to do it as affordable as possible. I have automated everything with pipelines and CloudFormation from Compil of new cardano node/cli to stake pool running.
Automating and designing this kind of architecture is my job, so it’s like playing home for me ![]()
I’m writing some tutorials as we speak, but please don’t use VPC peering or direct connect. It will cost you too much. A simple public/private subnet could do the job if you restrict BP to not use NAT GW too much.
You can also wrap the BP in a very tight security group and host it in public node, killing all the extra costs.
Using the AWS tools efficiently permit to even remove SSH so it’s very secure.
Also the most affordable way is to use Arm CPU, this is why I compiled it. I’ll distribute the executable in few days. My partner is working on our website, when it’s ready we will publish a lot of content to share.
I think block producer is too big, may be there is big loss of CPU.
In my opinion block t3.large - relay m5a.large is best practice.
If I got more delegated coins, there is any change of usage?
I’m using AWS right now with 3 t3.large you can see my cost are pretty insane: your methods seem complicated, so I hope I can understand it.

Which instances are you using, the new t6g? How has the performance been? I’ve compiled for ARM on those also, but I have not deployed yet.
same here no issue at all 
Thank you for the tips, that is amazing! Yeah, I definitely would want to cut down on some costs.
Our website is coming up and I’ll explain and distribute all the arm binaries on it. As well as some automation and technical things. Our goal is more to help you guys fish rather than giving you a pre-made template. I know too well how that might end, people will only start digging and understanding it when they have a real production issue. And this is how you have long and painful outages.
While if we explain, talk, and share, everyone can create their own version of it. Probably very similar in the end but it would add 2 benefits. The first and obvious one is that SPOs using this model will know what they are talking about for real, even without the pre-made scripts that I can see everywhere. The second one is that the more people we have with a good understanding, the more brilliant ideas we will have to share with the community and all improve capitalizing on them.
In a nutshell, to give a real answer to the points raised before. I currently use the r6g instances. This is very similar to the t6g you mention with some important differences.
The first letter of instances in AWS is the instance focus.
“t” is more focused on low cpu usage with some rare peaks. You earn cpu credit that you can spend on heavy load. If you spend too much credit compare to what you have in stock, the default behavior is to auto buy some. I’ll explain more later but you have the idea.
“m” is general usage, no cpu nor memory focus
“r” is for memory focus
“c” is for cpu focus
Cardano is having a really light weight on cpu but needs 8G memory. So r instances seemed like a good choice to me for the moment. I’m nearly sure Relay will be happy with that for a long time, BP is still using that, but can be changed to “m” if meeting limits (which I haven’t met at all !).
That would shrink your price and run perfectly well. There other steps in you design that you have to consider to stop paying for nothing. No Load Balancer, they are fantastic and I use them professionnaly a lot, but expensive for a simple cardano design. No NAT GW, too expensive. No VPC peering or transit GW, same, too expensive. Fence things bullet proof with security groups (again I’ll explain it later), use route53 DNS extensively, you will pay near $0 for a great outcome. I personnaly monitor with Cloudwatch, using only the free tier, it’s brilliant if you know what you are doing I even got SMS and email alerts for near $0. Again I’ll explain this.
I’m not trying to drag you for ages waiting for me to explain, it’s just that my job take lot of my time with my family and garden. But I promise to come back this week end and explain the base of it so it can really help you guys for real. If the website is not ready I’ll start here in the forum.
I’m going to bed, see you all tomo or sunday !
Keep the mojo !
Oh and to give you a feedback on price, just know that I’m currently running it for well under $100 / month (probably well under $1000 / year) all included (even the side things, domain name, website, etc …
)
Which rg6 are you using? 8 / 64 ?

Ola everyone,
hey @Anti.biz , wooo no man, the 8/64 is too powerful & too expensive (that often goes together). I’m currently using the smalest r6g.medium (1 CPU / 8G RAM). Cardano node really likes being at ease with memory, and it’s cpu footprint is really small.
I’m currently running around 1 or 2 % CPU and 60% memory, so it’s all good and stable. I’ve attached a small snap of the monitoring to show you.
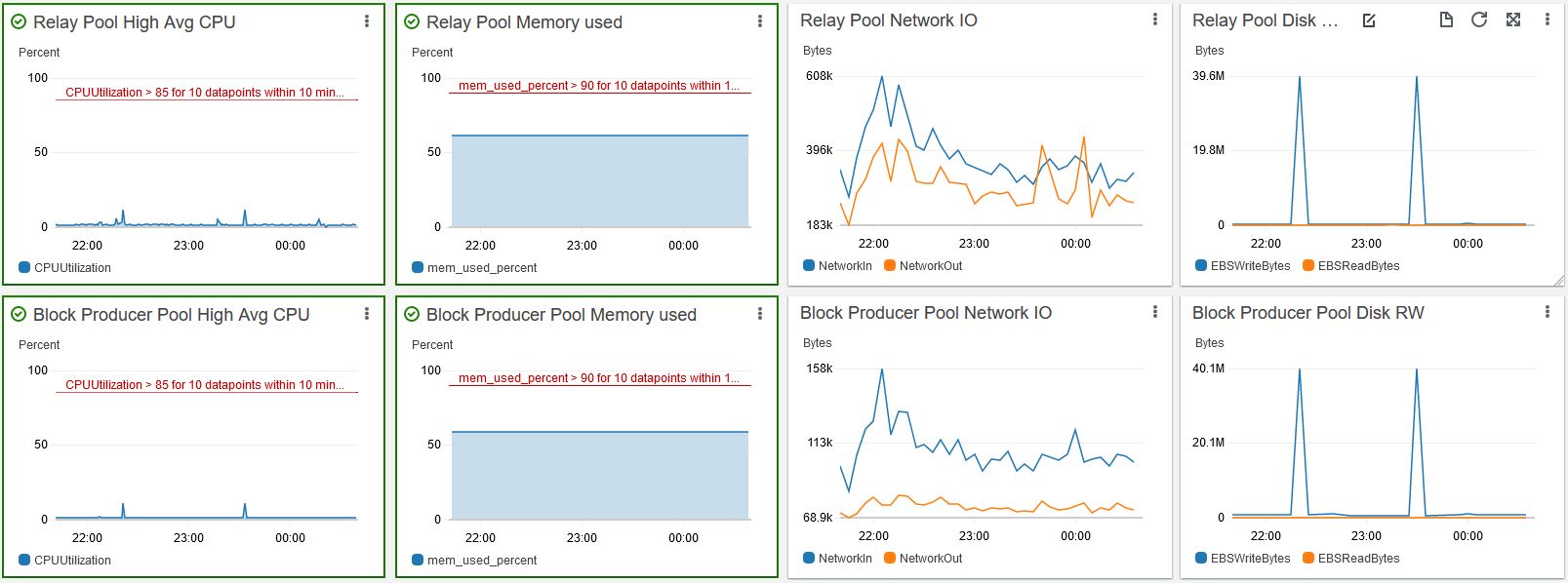
Time is UTC so it was taken right when I wrote this post.
The nice thing about Cloud and AWS is that you can change things when you are not pleased with them. So if those instances turn out to be too weak for some reasons I can change. As everything is automated (again I’ll show you how to do it), I just have to change the instance desired and re-release. There won’t even be a downtime … thank you AWS !
So back to important things, please find attached the Cardano CLI and NODE binaries for ARM64. They will be copied more cleanly on our website but right now at least that gives you a way to get them. You can also find the libsodium libraries compiled for ARM64 too. Just drop them in a path and update the environement variable LD_LIBRARY_PATH with it. (I’ll get in more details on this but that should get most of you going)
cardano-cli [aarch64] - 1.26.1
cardano-node [aarch64] - 1.26.1
cardano-cli [aarch64] - 1.26.0
cardano-node [aarch64] - 1.26.0
cardano-cli [aarch64] - 1.25.1
cardano-node [aarch64] - 1.25.1
cardano-cli [aarch64] - 1.25.0
cardano-node [aarch64] - 1.25.0
You can even choose which version you run, I personnaly run the latest validated so the 1.26.1
To come back to price, which is the central problem for most of us small pool not able to be self sufficient.
One r6g/medium 1cpu/8G RAM is $0.0604 in Sydney (where I decided to settle) and $0.0608 in Frankfurt (Europe example), some might be cheaper I let you discover (EC2 On-Demand Instance Pricing – Amazon Web Services)
Simple math using the $0.0608 (pessimist approach) price.
Average monthly cost = 0.0608 x 24 x 365 / 12 = $44
Now if you think you are going to keep it for a year (which I did) you can attach a saving plan, that shrink the price of this baby to $0.038 (I just checked) so:
Average monthly cost with saving plan: 0.038 x 24 x 365 / 12 = $27.74
It means that you are locked to pay for it for a year, weither you use it or not.
The only fears are usually:
- You will stop having a cardano pool => Well I can’t do anything for this one, this is between you and yourself

- You will need a bigger instance since now it’s consuming more.
Well that second one is more valid, and here is how to approach it in my humble opinion.
First your real commitment is only for 27.74 x 12 / 44 = 7.5 months
At that mark, you would have paid the same price on demand for a full year. So the last 4.5 months are “free”. If really you absolutely got to change (which I highly doubt) you will just, in fact, save less … not a big issue …
Also, if CPU started, for any reason really, to become a bottleneck you can update to any r6 and stay in your plan (the deal is for a full server familly irrespective of the size). Also I suspect it would be more the block producer node being cpu greedy, so we can upgrade just this one and add a relay with the extra instance.
Well as you can see the AWS Saving plans are a Win/Win. AWS got visibility, you got very interesting savings.
See ya all, perhaps we shouyl have another thread for all this.
Keep pushing !
And if you find it useful, an easy way to thank me if to get yourself some ADA and stake few on MADA1
Cardano-node I had to kill the process since it was in use even though I stopped the node which was weird. The Cardano-node /cli I was using was from the Raspberry PI guide and the git REV was 0000000000. Also your file was 3 times as large. So it seems better? I am not sure. Seems more correct.
![]()
my node was working until I swapped to the new binaries.
I think i found another location it needed to be copied:
:~/tmp$ sudo cp /home/xxx/tmp/libsodium.so.23 /usr/lib/libsodium.so.23
That seemed to do the trick, its working again. But the journalctl --follow information is moving very slow in comparison to how it was moving.

I reinstall libsodium , but it seems to moving slow still.
I removed my symbolic links not sure if I Was supposed to do that.

Hey @kaverne. Thanks for the details. This is really helpful.
Thank you mate, happy it helps.
Removing the symbolic link will just take more space and is less “pretty” but technically the system would have run it. So nothing dramatic, expect it’s not the right way to do things ![]()
libsodium have to be in the LD_LIBRARY_PATH.
The fact you have it when you are loggued and systemd does get it are 2 different things. Since you probably run cardano-node under another user right ?
My approach, and to avoid any confusion, is to drop the needed path straight in the systemd files, this way it’s always good for systemd.
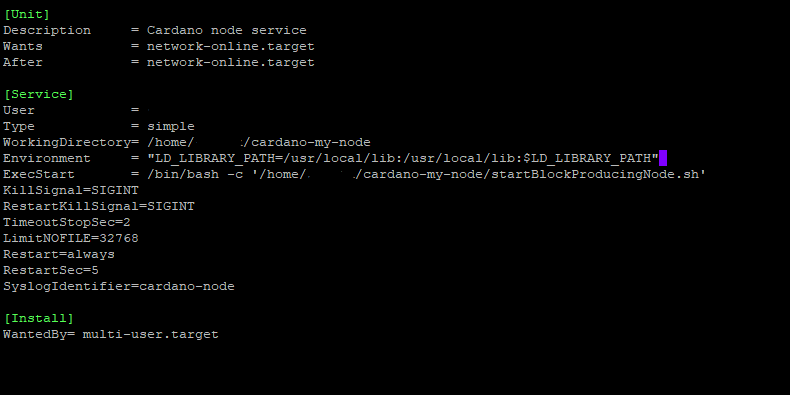
Here is my systemd for cardano-node if that can help you @Anti.biz
[Unit]
Description = Cardano Relay node service
Wants = network-online.target
After = network-online.target
[Service]
User = cardano
Type = simple
WorkingDirectory = /cardano
Environment = "LD_LIBRARY_PATH=/cardano/local/lib:$LD_LIBRARY_PATH"
ExecStart = /bin/bash -c '/cardano/scripts/startRelayNode.sh'
KillSignal = SIGINT
RestartKillSignal = SIGINT
TimeoutStopSec = 2
LimitNOFILE = 32768
Restart = always
RestartSec = 5
[Install]
WantedBy = multi-user.target
sudo systemctl daemon-reload cardano-node
Too many arguments.
(Im getting the above error)
systemctl daemon-reload doesn’t take argument from memory.
So just type
systemctl daemon-reload
And all services will be refreshed
For those still following this post I have posted the 1.26.2 arm compil in a separate post.
Our website is progressing : https://www.myadanode.com and will soon host all this and more tutorials to help your guys achieve automated cheap stake stacks