As for every release please find here the free to download binaries for 1.30.1 on ARM architecture (aarch64).
GHC used is version 8.10.7 from last august.
As usual it still needs libsodium, unchanged if you were already using it, but available here if you are new to this. (check my other posts for more details).
Enjoy, and if you feel like thanking us you can delegate few ADA to [MADA1]
PS: I know some people will insist you need more than 8G memory, but with proper tuning of Haskel you can run perfectly fine under 8G. Haskel version 9 should bring improvements on that matter. Check the forum for this, there is a fantastic post by @_2072
Happy to help. We have been running on the binaries we distribute free to all pool owners since the start of the pool.
We are not running on raspberry Pi though
Always getting the last word hey ? lollll
Whatever, someone came here to thank us for distributing the compiled arm64 binaries.
I appreciate the pat in the back, it stops there.
He said he tested the cli on a rpi3, noone said he running a pool on it.
A rpi3 is an ideal air gapped offline machine to RUN THE CLI on. Exactly as he said he did.
Anyway, thanks for supplying the binaries guys!
I’m not running our pool on RasPi (I’m just using those for my fermenter fridge and brewing beer )
So just for my knowledge, even if @lakcv was running a pool on RasPi, you seem to imply that would be an issue ? Why ?
I was implying that a rpi 3 would not work for use in a pool.
The rpi4 8gb RAM is no problem for using in a pool. There are several dozens of pools that I know of that run on these pis exclusively. They have millions of stake, are minting blocks and running relays just fine.
It just needs the right hardware settings, and pool parameters and they run just fine.
People build their pools with standard parameters, and then see they need to switch to 16 gb and tyen complain. However they don’t bother looking around to see if they can optimize their setup…
Oh yeah yeah sure.
I didn’t know the RasPi 3 wasn’t strong enough to hold the load. Yep you are right I know quite some pools and some “big” ones on that.
Will it be viable in the long run, time will tell. But plutus and smart contracts might generate more (not huge) cpu/memory needs. Wait and see
Good chat !
I’m currently researching into optimized Haskell GC settings for the Pi4. So far, I found that running a relay is no problem even without ZRam. Running block producer is a different story because it needs to run the lottery in real time once every second. The Haskell copying GC (i.e. the default) will halt the world for stretches of multiple seconds, which leads to “missed slots”. The newer non-moving GC still holds the world, but less. It generally keeps the mutator running (i.e. the node process) but has 20% higher memory consumption - also no good for a block producer.
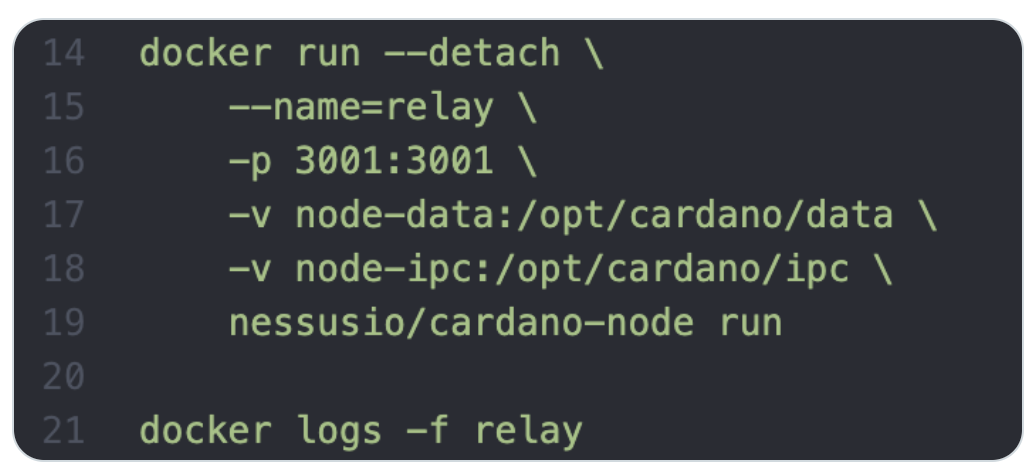
In case I find a good combination of ZRam and GC settings for the block producer, it’ll find its way into the nessusio docker image. You can monitor this work over here.
Astor also has scripts that can restart the block producer in time for the next block. Haskell GC deteriorates over time - it may hence not be necessary to find the silver bullet for long term sustained performance. Doing a restart a few hours before the next block is not ideal, but also leads to no missed slots for a couple of hours. This might be good enough for now (until Haskell improves its GC)
The above shows epoch/no slot, restart time, block time. You’ll notice that the restart happens 2h before the next block, unless this would interfere with a previous block. Two hours should give the node plenty of time to restart even with a dirty block store. I observed that major GCs happen a lot less frequently (if at all) during the first few hours of uptime - for me it turns bad after 8h or so. Unfortunately, I don’t yet have good and conclusive results worth publishing - each of my tests runs for 24h.
The Haskell GC reminds me of the early days in Java. Over time that got much better. Halting the world does generally not work so well for non-trivial processes - especially not, if there is a real time aspect to it. Nonmoving GC can keep the mutator (MUT) alive, but should not result in a drastic memory increase. GC should not increase memory over time for it’s own bookkeeping - that would be a memory leak. Not sure, if that is the case here - the node might cause the increase of memory that we see over time. In that case, we might be seeing a mem leak in the node, which would be low hanging fruit for improvement.


 )
)