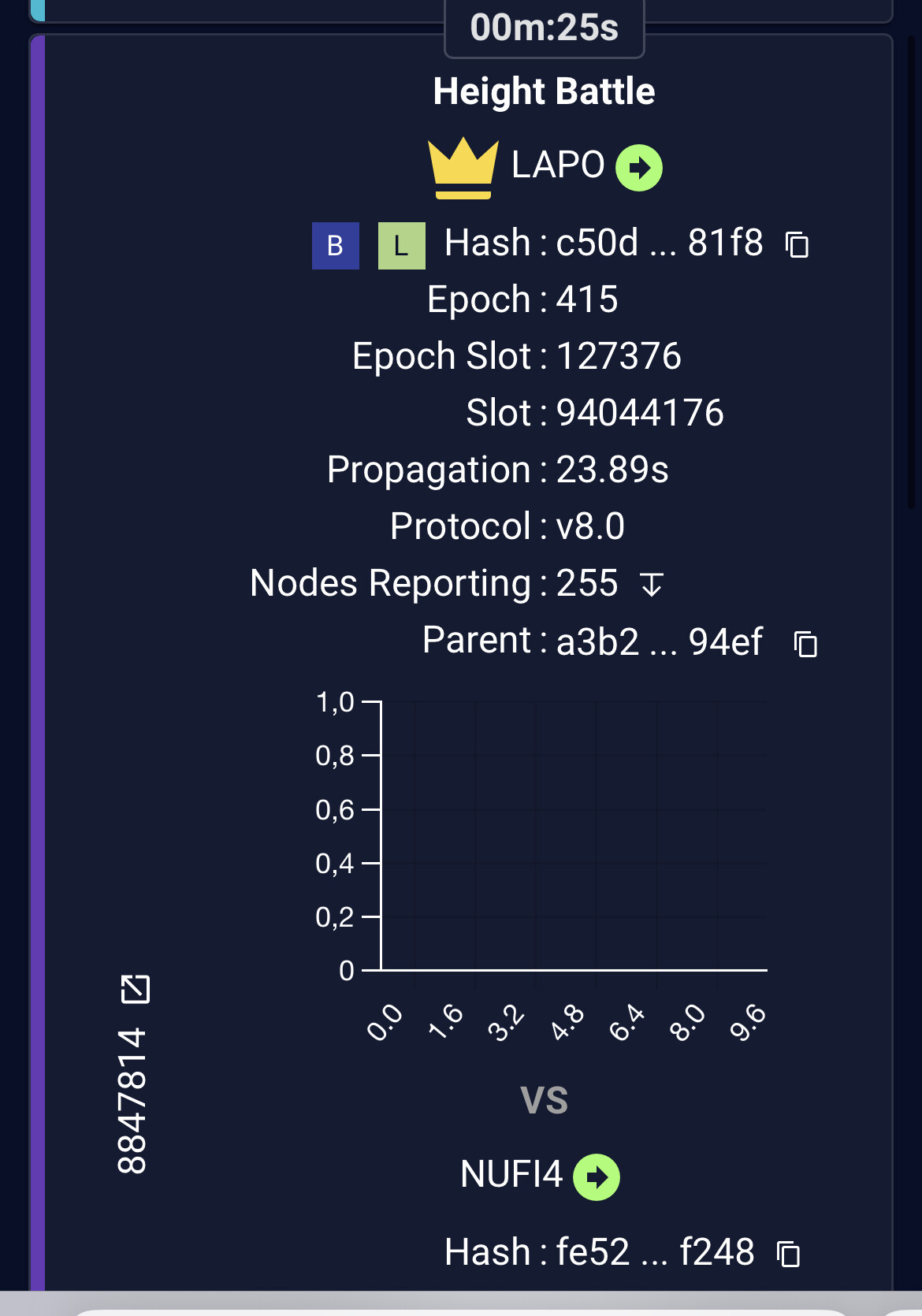
Firstly, you are correct about time sync being important so ensure you have this corrected on all your relays and block producer.
After that, the main things that will determine your block propagation times are:
- How connected your relays are to other external Cardano relays.
- Where your block producer is physically located.
Ensure you have lots of incoming / duplex connections:
This is what I have for 2 different relays.
Relay1
curl -s -H 'Accept: application/json' http://localhost:12788 | jq '.cardano.node.metrics.connectionManager'
{
"duplexConns": {
"type": "g",
"val": 24
},
"incomingConns": {
"type": "g",
"val": 20
},
"outgoingConns": {
"type": "g",
"val": 50
},
"prunableConns": {
"type": "g",
"val": 0
},
"unidirectionalConns": {
"type": "g",
"val": 46
}
}
Relay2:
curl -s -H 'Accept: application/json' http://localhost:12788 | jq '.cardano.node.metrics.connectionManager'
{
"duplexConns": {
"type": "g",
"val": 14
},
"incomingConns": {
"type": "g",
"val": 23
},
"outgoingConns": {
"type": "g",
"val": 50
},
"prunableConns": {
"type": "g",
"val": 0
},
"unidirectionalConns": {
"type": "g",
"val": 59
}
}
If you don’t have enough duplexConns / incomingConns then you need to look into that.
For example, this is what I get for a “hidden” relay that I have on my local network which is firewalled from outside connections. IE: It is not possible for any outside relays to initiate a connection to it:
curl -s -H 'Accept: application/json' http://localhost:12788 | jq '.cardano.node.metrics.connectionManager'
{
"duplexConns": {
"type": "g",
"val": 13
},
"incomingConns": {
"type": "g",
"val": 1
},
"outgoingConns": {
"type": "g",
"val": 50
},
"prunableConns": {
"type": "g",
"val": 0
},
"unidirectionalConns": {
"type": "g",
"val": 38
}
}
With this “hidden” relay you will see that it only has 1 incomingConns and that is from my own block producer. But it does have 13 duplexConns which have resulted from it initiating the connection out to an external relay and later that external relay agreeing to upgrade the connection between them to duplex. This means that those external relays should still be able to pull blocks from my “hidden” relay.
In all my relay configurations I have the following settings (which are the defaults):
"TargetNumberOfRootPeers": 100,
"TargetNumberOfKnownPeers": 100,
"TargetNumberOfEstablishedPeers": 50,
"TargetNumberOfActivePeers": 20,
The P2P mode actively manages it’s connections with other nodes depending on how reliably and quickly they provide blocks. You want your relays to be well connected and reliable so ensure they are always on-line with accurate clocks etc. I am not sure how long the memory is in the P2P mechanism in terms of how external relays will continue to view things. For example, if your clocks were out of sync for a while you may have a kind of “bad reputation” with other relays for a while??? But I am not sure how long this “while” is before they trust you again???
I actively monitor my block receipt delays on my various relays. I wrote a simple script to do this in a console. I have a ssh session open to each relay and use tmux with split windows so I can have multiple shells. I just leave this cn-monitor-block-delay script running in one so I can look at it whenever I want. The script actively tails your systemd log so depending on how you have that set up it may need to be run as root so it can see your logs. It could be written better. Feel free to steal any ideas and re-write your own version.
Here is what I see for one of my relays in Australia:
Hash=eb7129bd8c7ecc33985773a79e18afa700f1d4ac5c33ac55d3a57bbc34d06885,Slot=99878265,Block=9130895,Delayed=0.890
Hash=5ad9ab281cd0fe25ed6c9d1b47d6f77e501110ef0fc975610e2aef3bd5c96866,Slot=99878267,Block=9130896,Delayed=0.779
Hash=4977a74b45de3ae99cc78a292c262ce9083cb96efff8e137674e7d6bb4e9c712,Slot=99878285,Block=9130897,Delayed=0.780
Hash=ecd1d9ebe2bbdda5a8e7ff966c60e0d929015e2445f1571560c431491cec65c7,Slot=99878310,Block=9130898,Delayed=0.915
Hash=8ee6c64a122f9b4837dd4609879c0fbcd028ed1c8074e3741602497eaa75664b,Slot=99878315,Block=9130899,Delayed=1.000
And here are the same blocks for my contabo housed relay in USA:
Hash=eb7129bd8c7ecc33985773a79e18afa700f1d4ac5c33ac55d3a57bbc34d06885,Slot=99878265,Block=9130895,Delayed=0.775
Hash=5ad9ab281cd0fe25ed6c9d1b47d6f77e501110ef0fc975610e2aef3bd5c96866,Slot=99878267,Block=9130896,Delayed=0.457
Hash=4977a74b45de3ae99cc78a292c262ce9083cb96efff8e137674e7d6bb4e9c712,Slot=99878285,Block=9130897,Delayed=0.708
Hash=ecd1d9ebe2bbdda5a8e7ff966c60e0d929015e2445f1571560c431491cec65c7,Slot=99878310,Block=9130898,Delayed=0.507
Hash=8ee6c64a122f9b4837dd4609879c0fbcd028ed1c8074e3741602497eaa75664b,Slot=99878315,Block=9130899,Delayed=0.245
Notice how much the times can be greater for my Aussie relay, especially that last block. I sometimes see more than a second difference between my USA relay and my Aussie ones. This is despite the fact that my own ping times are consistently around 0.2 seconds between this USA relay and my Aussie ones:
cardano-cli ping -c 4 -h relay3 -p 2700
144.126.157.46:2700 network rtt: 0.206
144.126.157.46:2700 handshake rtt: 0.20584225s
144.126.157.46:2700 Negotiated version NodeToNodeVersionV10 764824073 False
timestamp, host, cookie, sample, median, p90, mean, min, max, std
2023-08-07 22:10:08.841429665 UTC, 144.126.157.46:2700 , 0, 0.207, 0.207, 0.207, 0.207, 0.207, 0.207, NaN
2023-08-07 22:10:09.04906493 UTC, 144.126.157.46:2700 , 1, 0.206, 0.206, 0.207, 0.206, 0.206, 0.207, 0.001
2023-08-07 22:10:09.257157769 UTC, 144.126.157.46:2700 , 2, 0.206, 0.206, 0.207, 0.206, 0.206, 0.207, 0.001
2023-08-07 22:10:09.464952304 UTC, 144.126.157.46:2700 , 3, 0.206, 0.206, 0.207, 0.206, 0.206, 0.207, 0.001
I guess that each relay can only feed blocks to other relays at a certain rate and it can’t do too many at once, so this creates additional delays which cardano-cli ping doesn’t account for.
None of the above will tell you about your own block propagation times. You will need to get such information from other relays and pooltool does provide such information from information it collates from pool owners that do “send tip” data. That same script of mine does provide a “-s” switch to send your tip data to pooltool. You will need to configure things in a basic “my-cardano-node-config.json” file for it to work properly though. It just needs something like:
{
"poolId": "08f05bcfaada3bb5c038b8c88c6b502ceabfd9978973159458c6535b",
"pooltoolApiKey": "blahblahblah"
}
You will need to create an account on pooltool to get your own pooltoolApiKey.
I am not saying that you should send your tip data to pooltool though. I currently am not, but I have in the past. I think it is less important now that most pool operators are using P2P mode. Previously when most people were manually configuring their relay connections, many (most?) were using a centralised provider to download their topology file. This meant that they were relying on this centralised provider for that configuration. Which external relays it put into the topology files it provided was therefore dependent on which relays that centralised provider “preferred” to hand out to others. This is why I was providing my “tip delay” data previously because I wasn’t sure how this centralised provider would “prefer” to send my relay connection details to others??? So, I thought it best to play nice and do what everyone else was doing just in case the centralised provider decided not to like my relays. Everyone running P2P mode fixes that centralised control problem.
Hopefully that gives you a few ideas about how to look into the problem.